Decision-Oriented Dialogue for Human-AI Collaboration
Abstract
We describe a class of tasks called decision-oriented dialogues, in which AI assistants must collaborate with one or more humans via natural language to help them make complex decisions. We formalize three domains in which users face everyday decisions: (1) choosing an assignment of reviewers to conference papers, (2) planning a multi-step itinerary in a city, and (3) negotiating travel plans for a group of friends. In each of these settings, AI assistants and users have disparate abilities that they must combine to arrive at the best decision: assistants can access and process large amounts of information, while users have preferences and constraints external to the system. For each task, we build a dialogue environment where agents receive a reward based on the quality of the final decision they reach. Using these environments, we collect human-human dialogues with humans playing the role of assistant. To compare how current AI assistants communicate in these settings, we present baselines using large language models in self-play. Finally, we highlight a number of challenges models face in decision-oriented dialogues, ranging from efficient communication to reasoning and optimization, and release our environments as a testbed for future modeling work.
Definition
We define decision-oriented dialogue as a class of tasks in which users and assistants must collaborate to make structured decisions. This may be viewed as an extension of task-oriented dialogue and is also a subclass of mixed-initiative dialogue. In a decision-oriented dialogue, there is an objective measure of utility based on the final decision a user reaches. This allows us to automatically evaluate the quality of AI assistants in these settings.
Tasks & Data
We designed three decision-oriented dialogue tasks, along with corresponding interfaces for data collection. (1) In Optimization, two agents take on the role of conference area chairs, assigning reviewers to conference papers when each agent has only has partial information about reviewer-paper affinities. (2) In Planning, an assistant with knowledge of a city must assist a human with building an itinerary based on their preferences. (3) In Mediation, multiple users must collaborate with an assistant in order to resolve group scheduling challenges.
We collected human-human dialogues for each of these tasks using the interfaces below:
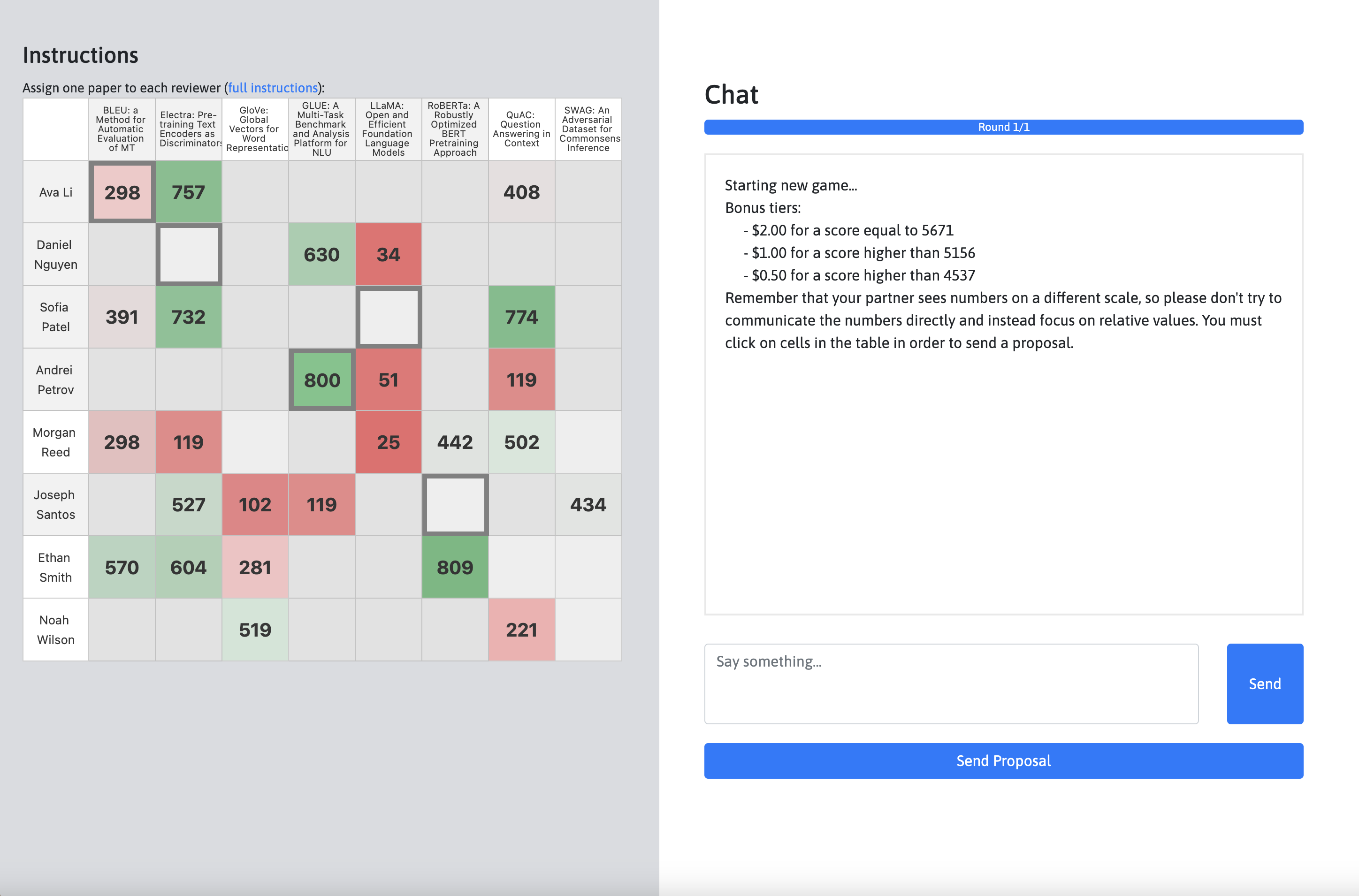
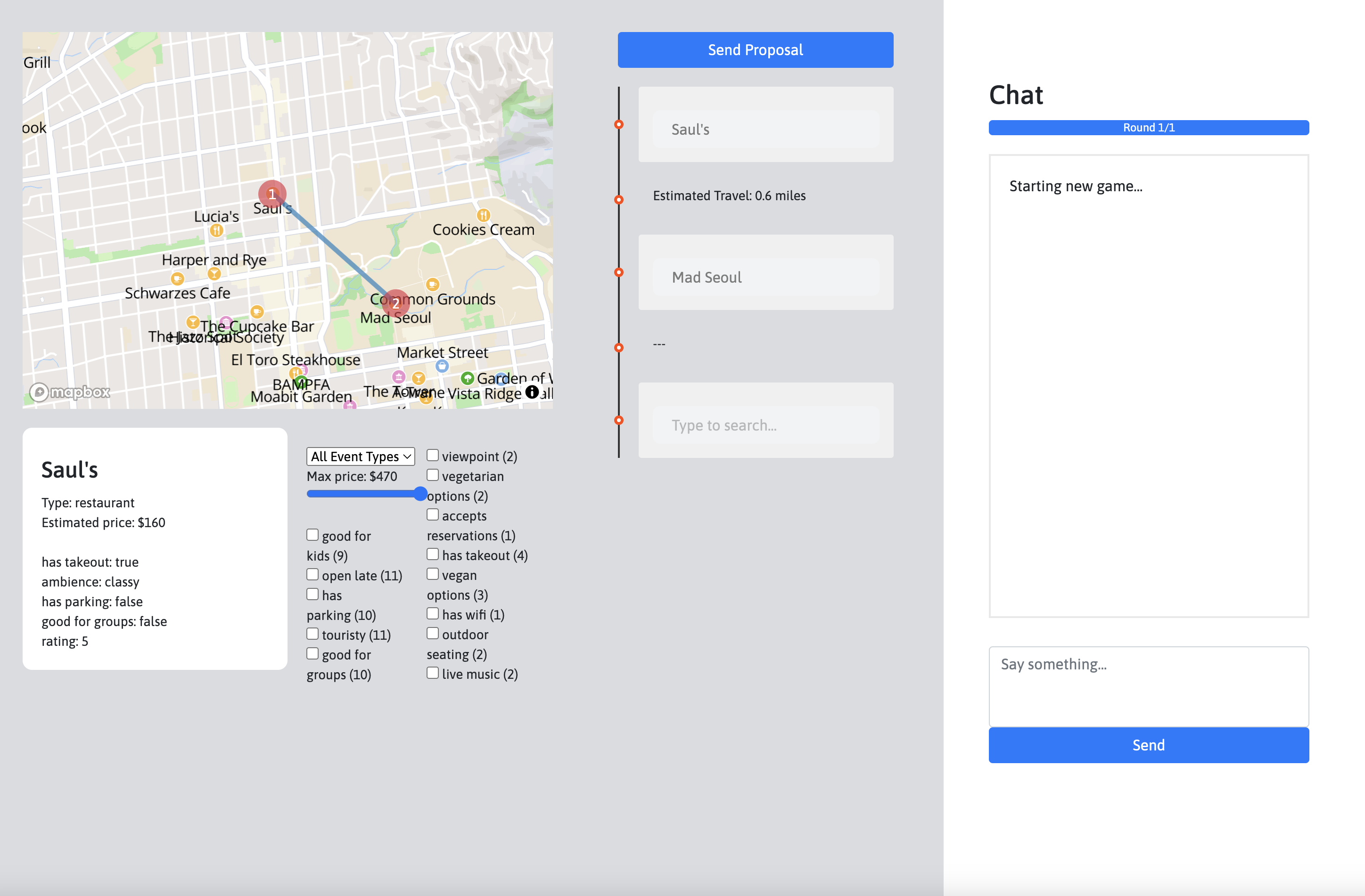
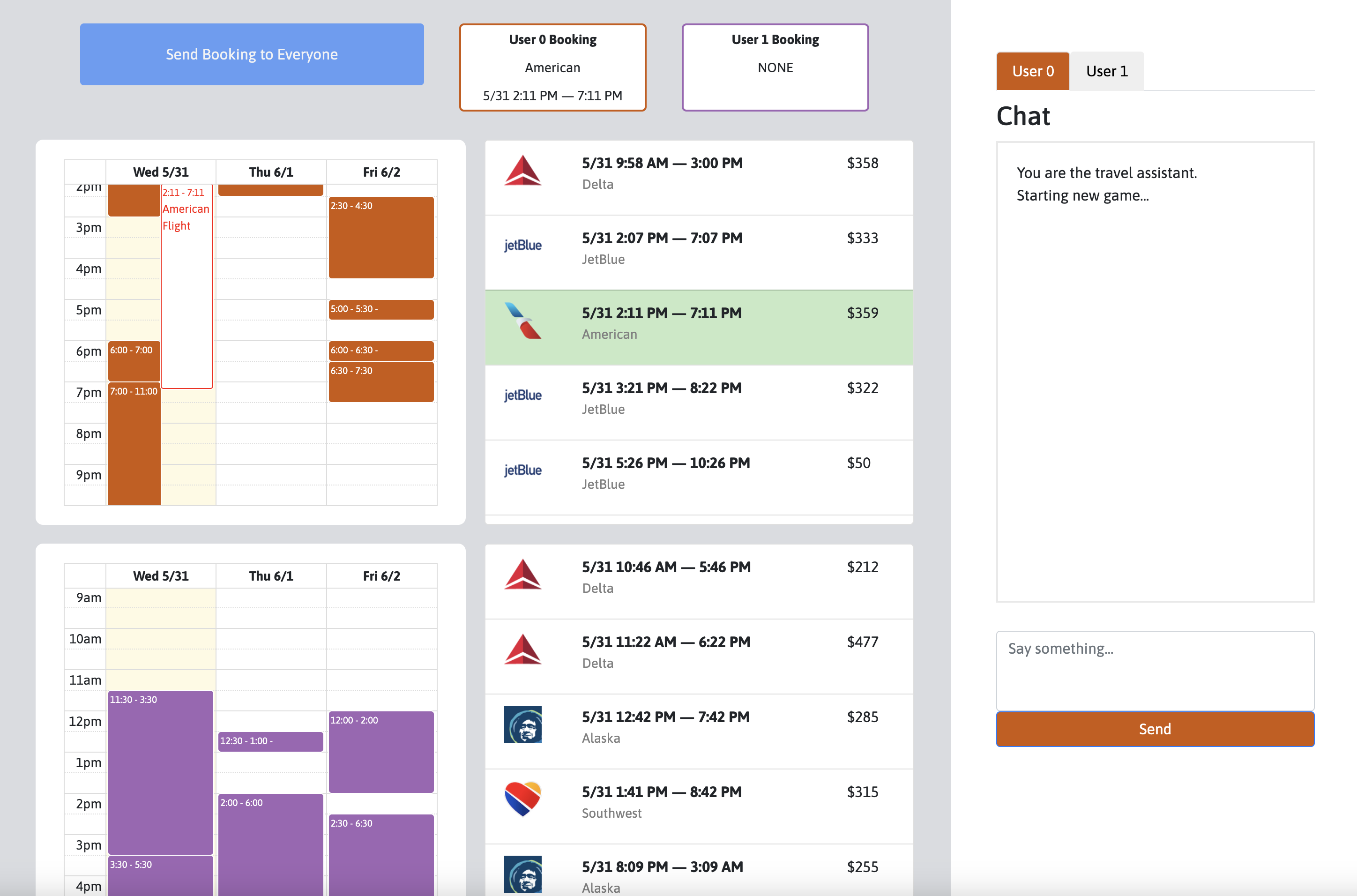
In order to view an environment, click on the corresponding link above multiple times. You will need to open as many browser windows as there are players in the game, which is two for Optimization and Planning, and three for Mediation.
In total, we collected 409 human-human dialogues consisting of a total 5253 messages and 58K words. Data is available here.
Models & Environments
We also release environments which allow language models to access the same information that humans can see in the web interfaces above. In the case of Planning, these environments include additional tools which allow language models to query for external information, because the information cannot be linearized into the context length of most models (e.g., 4096 tokens). We then run GPT-3 (text-davinci-003) on all three tasks in self-play and compare its performance to that of humans.
Results
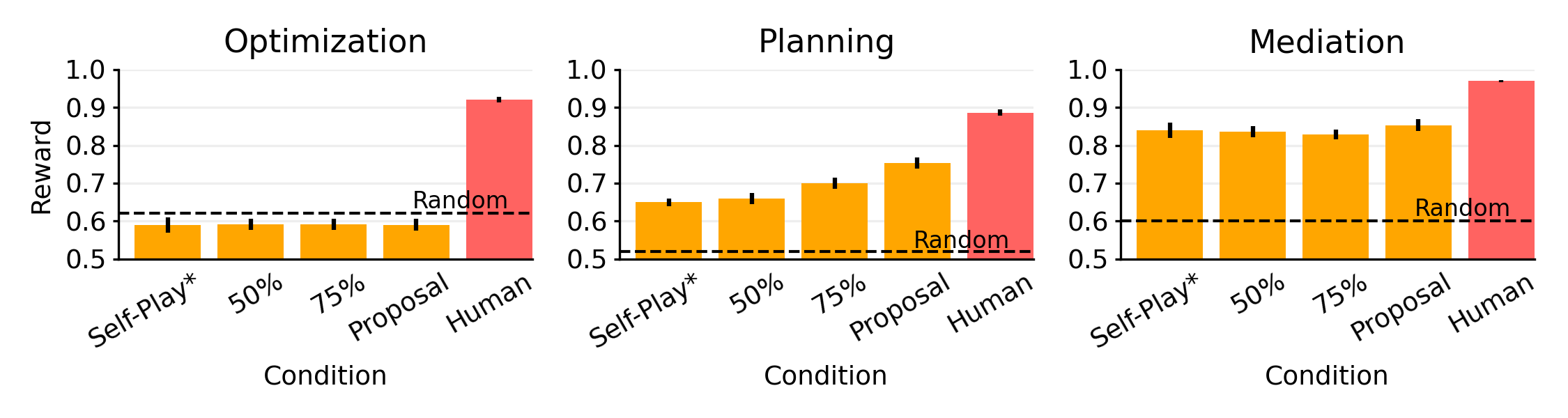
We find that GPT-3 (in self-play) has longer dialogues than humans while achieving lower scores on all of our tasks: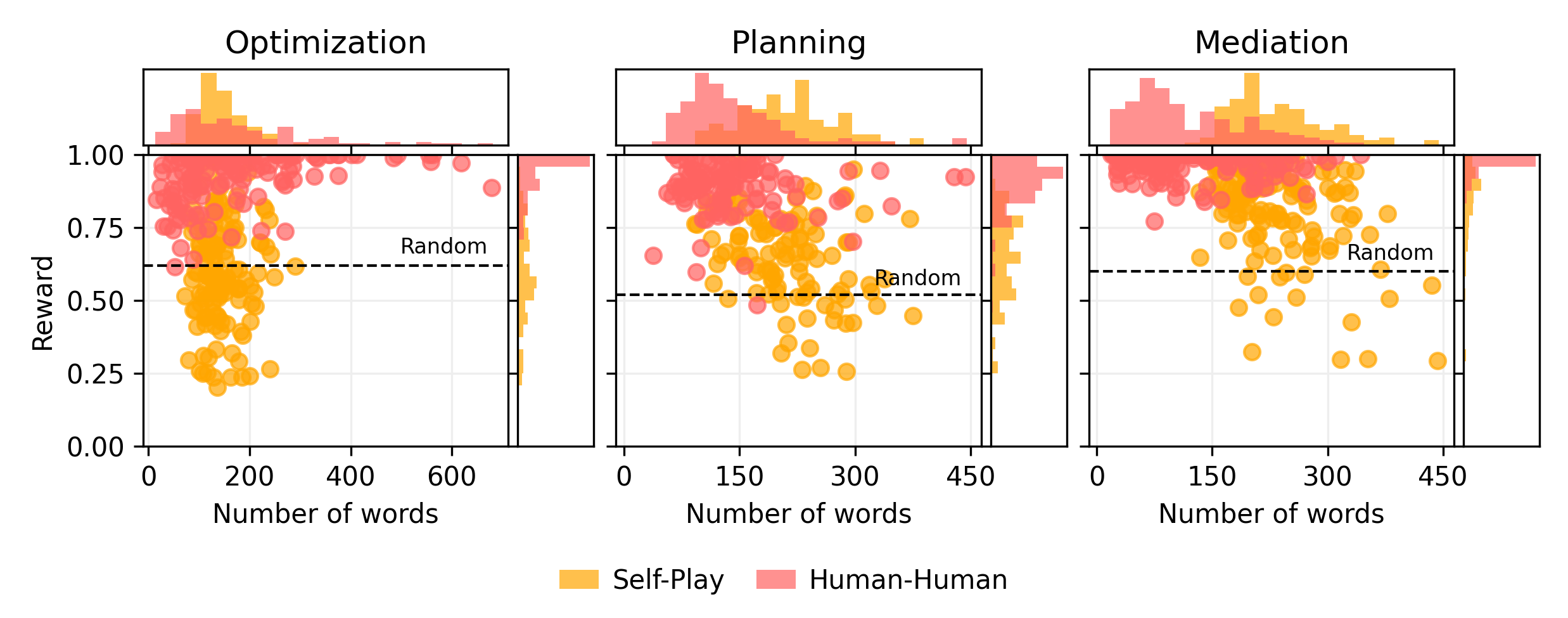
We also include results for a new evaluation technique called prompted self-play (PSP). In this condition, we prompt models with 50% or 75% of corresponding human-human dialogues and let models continue from these prefixes in self-play. We also consider a proposal condition in which models have access to all messages in a human-human dialogue except the final proposal and must generate the final proposal themselves. Results are shown below: